



Next: 7.2 A Standard -Body
Up: 7. A General -Body
Previous: 7. A General -Body
In the first part of this book, we have offered a few quick-and-dirty
programs that work fine for initial explorations. We were able to
study stability aspects of various 2-body and 3-body systems, both
with respect to numerical instabilities as well as physical
instabilities. Many more situations could be easily explored, using
these programs, and we hope that the readers will have tried their hand
at some other configurations, starting from different initial conditions,
for 2 or 3 or more bodies. Starting from hermite2.C, for example,
it is easy to change the value of n in the first line, and to
replace the explicit assignment of positions and velocities by other
values for all st n particles.
However, it quickly becomes tedious to have to change the program,
each time we want to integrate from a different starting position.
Also, there are many other improvements that can be made to the code,
as anyone with even modest programming experience will have noticed.
In this second part of our book, we will begin to add more structure.
Once we have structured our codes in a more modular and flexible way,
we are in a position to carry out some real research projects with
astrophysical implications. While simulating some real stars systems,
we will soon realize that we will have to extend the complexity of our
codes. While we will make the switch to variable time steps already
in this chapter, we will later find a need to assigning individual time
steps to each star. Also, we will introduce special coordinate
patches for interacting group of stars. We will take these two steps
in later volumes in our book series.
Here is a quick overview of a wish list for improving the structure of
our computer codes. We will address some of them fully in this book,
while we leave other items partly or completely to other volumes.
- comments
- So far, we have not included any comments in our codes. In an attempt
to keep the codes short and uncluttered, we wanted to show the flow of
the statements directly, given that most codes could fit on one or two
pages. But when the codes became longer, it was high time to put in
comments, and we will do so from now on.
- functions
- So far, we have written each program as a single function call to main(), without trying to split up the program into smaller pieces.
For the first few codes, this was fine, and it kept everything light
weight. But for the later codes, spanning a few pages, it would have
been better to start dividing the functionality over separate functions.
For example, in leapfrog2.C, we calculate the accelerations early
on in the code, and then in the same way at the end of the main
integration loop. Putting those statements in a function, and calling
that function once before the loop and once in the loop makes the code
both easier to understand and easier to debug. In addition, it is
likely that we will use such a function in other codes as well.
- structured I/O
- In our examples so far we have used only a very rudimentary form of
I/O (input/output). We wrote our results in the form of a list of
positions and velocities to the standard output stream, and we wrote
some energy diagnostics to the error output stream. And we used input
only interactively, to prompt the user to provide a few parameters.
It is much better to define a unique
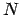 -body data format, which
includes other variables besides
-body data format, which
includes other variables besides 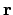 and
and 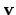 , such as masses,
time, and perhaps additional information. Once we write the results
from an integration into a file, we can then read in that file again
when we want to continue that run. This leads us to:
, such as masses,
time, and perhaps additional information. Once we write the results
from an integration into a file, we can then read in that file again
when we want to continue that run. This leads us to:
- pipes
- The notion of pipes in Unix allows one to redirect the output of
one program as the input of another program (`piping' the results from
one program to the other, as it is called). For example, it would be
nice to pipe the results of a program generating initial conditions
directly into an integrator, and to pipe the results of the latter
into an analysis program.
- command line arguments
- Typing in parameters by hand, after being prompted by a program,
gets tedious very soon. It is also inflexible, in that it doesn't fit
very well if we want to write shell scripts to run a bunch of programs
in laboratory fashion. A better way to pass parameters to a program
is by providing arguments directly on the command line. Unix has a
default protocol for doing this, and we adapt that usage in the
following programs.
- using a Makefile
- When the number of files in our working directory grows, we may lose
track of which program needs to be recompiled. To automate this
process, we introduce the notion of a Makefile below. The real
strength of Makefiles will become apparent only later, but already at
this stage is can be helpful.
- test facilities
- Soon our codes will reach a level of complexity where it becomes
difficult to convince ourselves that the code is really doing the
right thing everywhere, giving the correct answers in the end.
The best approach is to develop a slew of standard tests, together
with a form of scaffolding that enables these tests to be run
automatically, each time we make changes to our code.
- using the C++ STL
- So far, we have used only the bare bones part of the C++ language. In
some of the programs below we will introduce a convenient extension to
the C++ core language, in the form of the Standard Template Library
(STL), which is included in every modern C++ compiler. It gives us a
quick and well-debugged and often (but not always) efficient way to
get standard tasks done quickly.
- C++ classes
- The central feature of C++, as an object-oriented language, is the use
of classes, ways to encapsulate objects. Since we need to build up
some considerable experience with
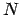 -body codes in order to know what
type of objects to construct, we postpone the introduction of classes
until later in this book.
-body codes in order to know what
type of objects to construct, we postpone the introduction of classes
until later in this book.
- error checking
- Any robust code will do lots of error checking. Ideally, every
function should make sure that the data it gets fed are of a form that
is valid for the operations that it wants to do on them. Since error
checking, and even better, error handling (following up an error in
the proper way, once it occurs) complicates a code considerably, we
postpone this until somewhat later.
- more flexible data format
- As we discussed earlier, it would be nice to give each star
considerable autonomy by building in some form of artificial
intelligence to let stars decide when to do what and how to
report on it. For this to work, a minimal requirement is a
flexible way for reporting unforeseen events, and this requires
considerable flexibility in the data formats used. We will
later give an example later of `stories' that are attached to
each star's data.
- more flexible command line options
- The Unix-based one-letter-only style of command line options that we
introduce below is far from ideal. Later we will provide a more
flexible way of handling arguments on the command line.
- more detailed help facility
- For now, asking for help will result only in a list of command line
options, together with a brief indication of what they do. It would
be better to provide several levels of help, allowing the user to get
more detailed information when needed. This leads to:
- documentation
- At a minimum, a good software environment should have a manual page
for each program. Even better, groups of programs should be described
as to their purposes and the way they can work together. This leads to:
- construction of a software environment
- At some point, when we have written various integrators and a number
of programs to generate initial conditions and to analyse data, it
will become too much of a clutter to keep everything in a single
directory. We will need to provide more structure for the way in
which we store our tools, and the way we intend them to be used. This
leads to:
- multiple files
- We mentioned under `functions' above the desirability to recycle code
by creating functions that can be used for different applications. If
we compile such a function in a separate file, it will be easier to
link it to other codes that use it. This leads to:
- libraries
- An extension of the previous concept, in which a group of related
functions is compiled into a library, which can then be linked to
other codes that use some of the functions collected there. Having
various libraries and many files requires significant bookkeeping to
be done to guarantee that everything is consistent and up to date.
This leads to:
- version control
- For a software environment under development (and every healthy
environment is constantly under development!), it is useful to be able
to reconstruct older versions, and to keep track of the latest
developments. CVS, short for Concurrent Versions System, is a useful
package for doing all this. It also allows several people to write
code asynchronously within the same software environment, since it
will flag any collisions stemming from potential multiple edits. More
recent alternatives are available as well, such as SVN, short for
Subversion, which allows more flexible ways to rename files and whole
directory structuress.
- autoconfig
- A related useful facility is `autoconfig', which allows a user to
install a software environment on an (almost) arbitrary platform,
without any trouble. As the name implies, this program does an
automated check to see how your particular system is configured, and
it then sets up your copy of the software environment in such a way
that it fits your environment.
- parallelization
- With most modern computers distributing the running of a
time-intensive program over several processors, it is important to
give guidance to the compiler as to how to break up a large program
into chunks that can be executed safely in parallel. Later we will
discuss how to modify our
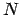 -body codes to make use of both
small-scale and large-scale parallelism.
-body codes to make use of both
small-scale and large-scale parallelism.
- special-purpose hardware
- Another way to greatly gain in speed is to use dedicated hardware,
constructed specifically for the problem at hand. For the
gravitational
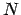 -body problem, the GRAPE hardware developed at the
University of Tokyo, provide such a function. We will discuss issues
connected with the use of one or more GRAPE boards.
-body problem, the GRAPE hardware developed at the
University of Tokyo, provide such a function. We will discuss issues
connected with the use of one or more GRAPE boards.
- a dedicated plotting package
- The time will come that the use of a canned plotting package, like
gnuplot, is just too inflexible for our particular needs in analyzing
the results of
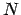 -body runs. At some stage we will introduce a
version of a plotting package, dedicated to the analysis of
stellar dynamics simulations of dense stellar systems.
-body runs. At some stage we will introduce a
version of a plotting package, dedicated to the analysis of
stellar dynamics simulations of dense stellar systems.
- a scripting language
- Around that time, if not earlier, the need will be felt for a
scripting language that is more powerful than the simple use of shell
scripts.
- archiving
- Finally, when we have an efficient and detailed software environment
for doing cutting-edge scientific research, we will want to perform
large-scale simulations. When some runs will take weeks or months to
run on the world's fastest computers, it is important to have ways to
store the massive amounts of data in such a way that we can later
query those data in flexible and efficient ways. Archiving and data
retrieval as well as more fancy operations like data mining then
become serious issues.
Next: 7.2 A Standard -Body
Up: 7. A General -Body
Previous: 7. A General -Body
Jun Makino
�$BJ?@.�(B18�$BG/�(B10�$B7n�(B10�$BF|�(B